Why Our Infra Integration Code Keeps Changing
Years back, we had a maven dependency that was part of a large project for many years. It was coming from a few Java versions back in the past (Those were the days when a new release of Java was a rare event to witness). But it was working just fine, no tests failing, nothing new needed. It didn’t make any stability or performance problem at all. It didn’t have any dependency that might need an update. It was a dream dependency. I never ever needed to touch it. Sure we had much more active dependencies as well. While this one was extraordinary, it was also an example of how piece of working industrial code can survive without needing a change, if all conditions happen.
In the end, some code ages well and some code gets completely rewritten. There are many reasons that play a role in this. Sometimes our requirements change, sometimes technical debt accumulates to a point it can’t be overlooked anymore. Sometimes we are hit with defects, bugs. There are many cases that happen outside our control. The nature of software ever changing as long as it lives, kind of internalized by most people. What we need to learn, is to deal with constant change.
Infrastructure, cloud, automation, integration code take their fair share from this entropy as well.
However many people tend to consider application code to be hot and infrastructure/integration code to be rather cold. Main reason is the false assumption that infra/integration is setup always once (even for cloud) and then the code stays mostly unchanged.
This is far from reality and the focus of this post is the reasons.
In the rest of the post, when I say integration code I mean the code that helps creating functioning flows by combining APIs of services together.
Can infra / integration code be mostly static ?
Let’s see if this assumption has any ground. I will say, yes, it is possible under certain conditions. I believe this originates from heavily on-prem experience.
Infrastructure automation in an on-prem environment has different characteristics. First of all, the business allows (sometimes obligates) running all in on-prem.
Next, the lowest layer it deals starts with hardware with specs we choose. The software is added/removed/upgraded only when we decide to upgrade. Items may stay same because we can virtually disconnect them from the world. There is never a case like we have to change our code because after a certain date our cpu will stop running. Or, there is never a case where a software we install and configure will stop functioning even if we are perfectly happy with it.
There are tons of institutions out there still using couple of decades old software pieces (not kidding) because they work fine for them and nobody has any further expectations. The fact that no further feature needed, is a key enabler for this. It’s very rare, but happens.
So, if we have full explicit control on what can get inside and keep future needs at bay, we can keep using same code, including infra/integration very static.
Since more than a decade, we are working with software services as a result of growing b2b maturity in the industry. 20 years ago, everybody had to run their own mail services, web services, code repos, code repos, databases, payment systems … But those are not the business for most. An estate agent owning lifecycle of it’s own email service is similary strange for them to run their own printing press for ads.
Infrastructure / Integration Code against cloud/SaaS solutions
Stepping more in to the world of B2B software services, many of us have infrastructure that utilizes some services from public cloud providers, source code repository services, monitoring services, incident management, document management, messaging systems, crm, erp, itsm, iot … The list goes on.
We interact with all of them via their APIs. This contract is not as hard as a contract we have with a hardware/software installed on prem. The service and its API keep evolving. New features, services are added. Bugs are fixed. Some features are deprecate, functionality is changed. Although there is a substantial effort to keep compatibility at high level, it’s impossible to have it always.
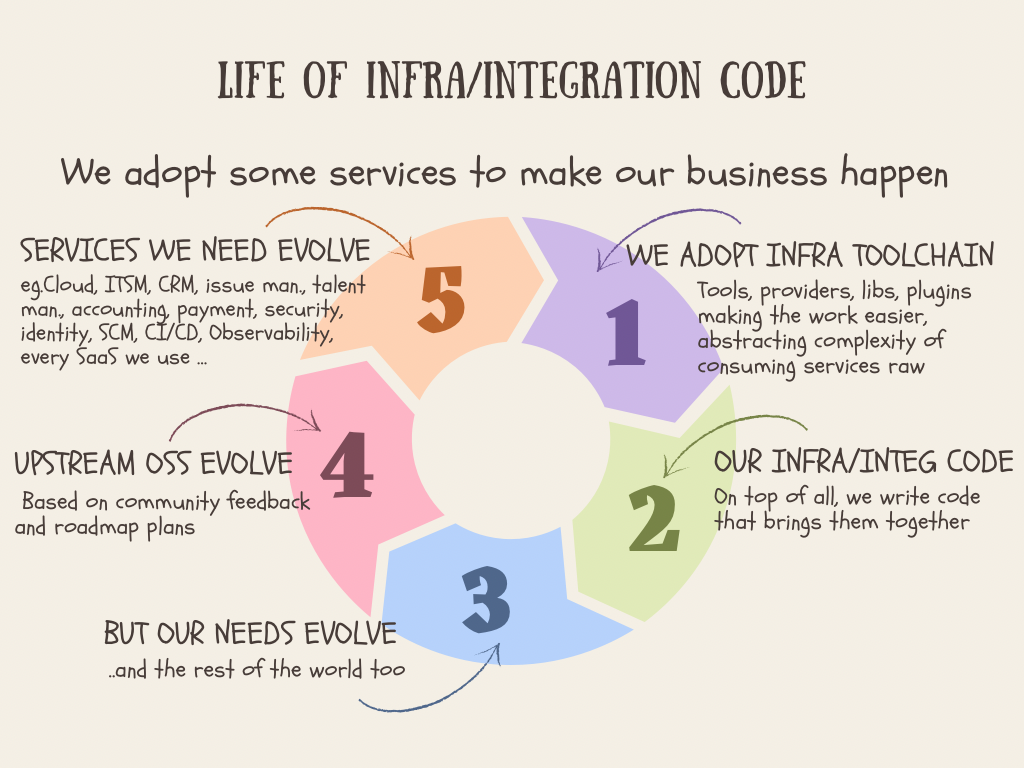
Infra code cycle
The main difference between on-prem based world-isolated infrastructure where we own everything and the one that leverages B2B services is, services keep evolving outside of our control.
As services evolve, the toolchain, integration libraries, anything that acts as a glue also evolve. Like other software, those have their own support period. It’s certain that after a few months to a year, our code and the dependencies (toolchain and their plugins, providers etc) will start showing their age. There will be a time where no features are added, bugs are appearing, functionality degraded (because the actual service keeps moving), security issues getting found.
Can we have any control on this ?
No. We can’t stop B2B services from changing. We can’t freeze the toolchain and dependencies. Moreover, toolchain and dependencies start functioning like a service, because they are coupled with the functionality they are abstrating/simplifying and whenever upstream B2B services change which makes them change.
Summary
Sometimes people expect the code written for the infrastructure and integration to be rather static. It’s understandable that heavy/isolated on-prem experience where we can assert our control on every change, may be a cause for this expectation. However a business that leverages professional B2B services for stuff like source code management, public cloud services, catering services, cleaning services, recruitment services, messaging services … lives in a world where such services and their toolchain keep changing (in different speeds), making it impossible to tolerate a long term technical debt on infra/integration code.
Accumulation of such debt is similarly critical as the technical debt in our product, if not more. Issues in infrastructure and integration code has the potential of bringing evertyhing on to its knees.